Notes on cache coherence
2024-09-21 |these are ongoing notes on cache coherence, updating regularly.
Modern processors maintain private caches per core to speed up memory accesses. However, these private caches can contain the same cache location, a problem arises when two processor can see different values for the same cache location.

Each core has private L2 and L1 caches and shared L3.
Cache coherence algorithms maintain two invariants [Jerger and Martonosi]:
- Single-write, multiple-reader (SWMR) invariant: In a given time point only a single writer may write to cache-line while multiple readers can read simultaneously.
- Data-value invariant: The data value at the start epoch should be the same as the last write epoch.
These invariants are implemented inside of the coherence controllers.
- Cache controller → in the cache
- Can intercept
ld/stinstructions. - Can see messages on the bus.
- Can intercept
- Memory controller → LLC/memory
There are different schemes to implement the upper two methods:
- Snoopy-based: Snoop (watch) system bus to check if there is an ongoing transaction that is related to its own cache.
- Directory-based: Central place for checking coherence status
Mechanisms
Snoopy-based
TLDR: Whenever a cache line changes its state broadcast to all other cores.
- Extremely popular before large-scale systems (after 20 cores it’s not scaling) [].
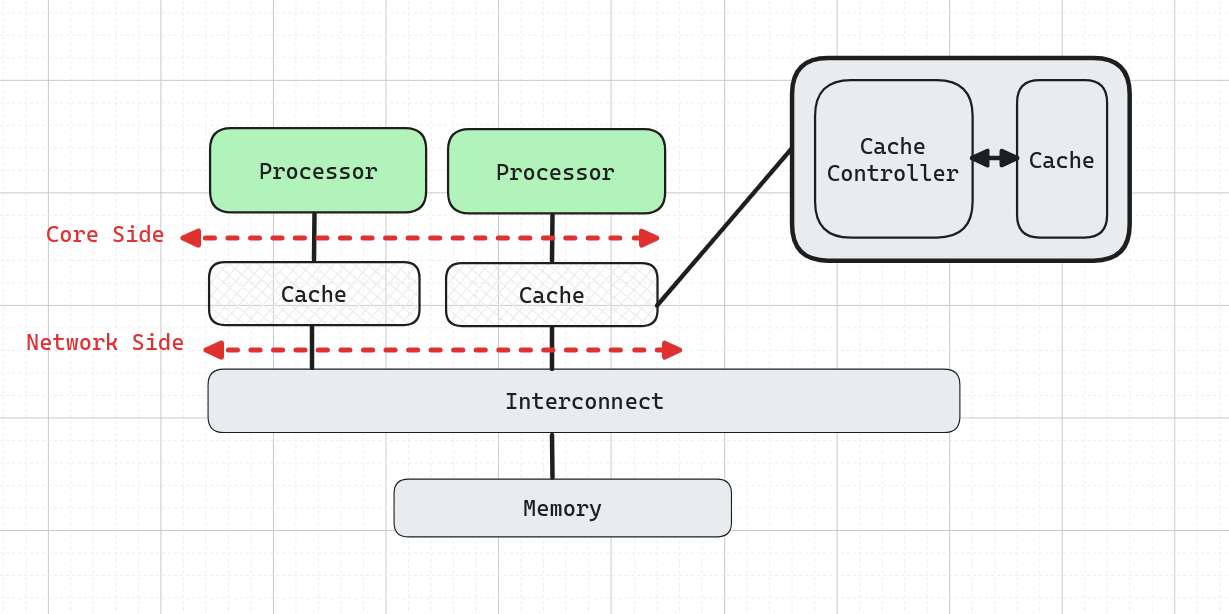
- Cache controllers snoop all transactions from the shared bus.
- Core side intercepts each load/store transaction while the network side maintains coherence-related communications with other cores. → This will create an interference between the cache and processor. Because now cache is used both to serve the processor and maintain coherence. []
- This can be solved by duplicating the tags of cache-line, to have a separate lookup for coherence. However, implementing this is not an easy problem.
- Not scalable due to bus contention.
Directory-based
TLDR: Instead of broadcasting to cache state all other cores, send the cores that contain that particular cache line.
Similar to phonebooks, little piece of SRAM that is a directory of the sharer of a particular cache block. We don’t need to see all transactions now. Previously, the bus was the bottleneck, centralization point. Now all caches will going to send messages to the coherence directory. Now there is no need to watch all the transactions on the bus, now communicate when necessary.
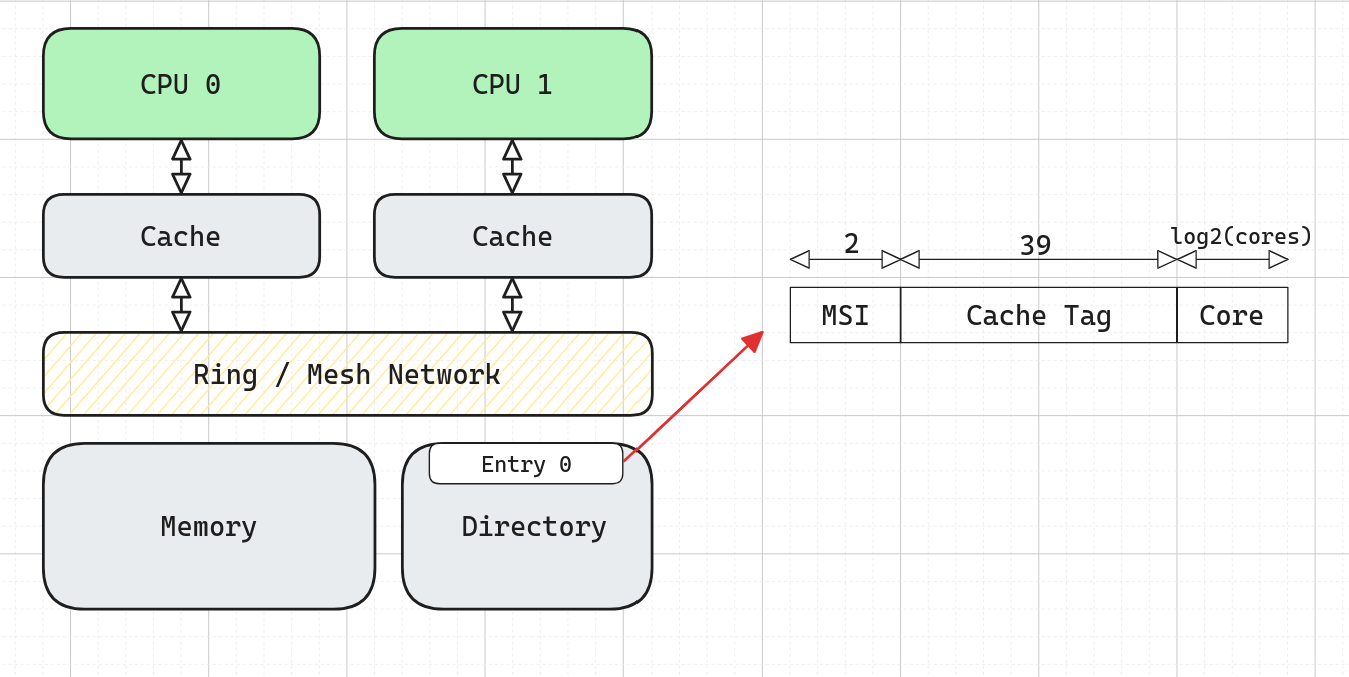
The directory stores all tags that are present in L1 caches. Set-mapping functions must be same.
Example: If we have 2 CPUs with 4-way L1 caches then directory must be 8-way associative. However, the width of the directory is not sustainable in terms of power and latency.
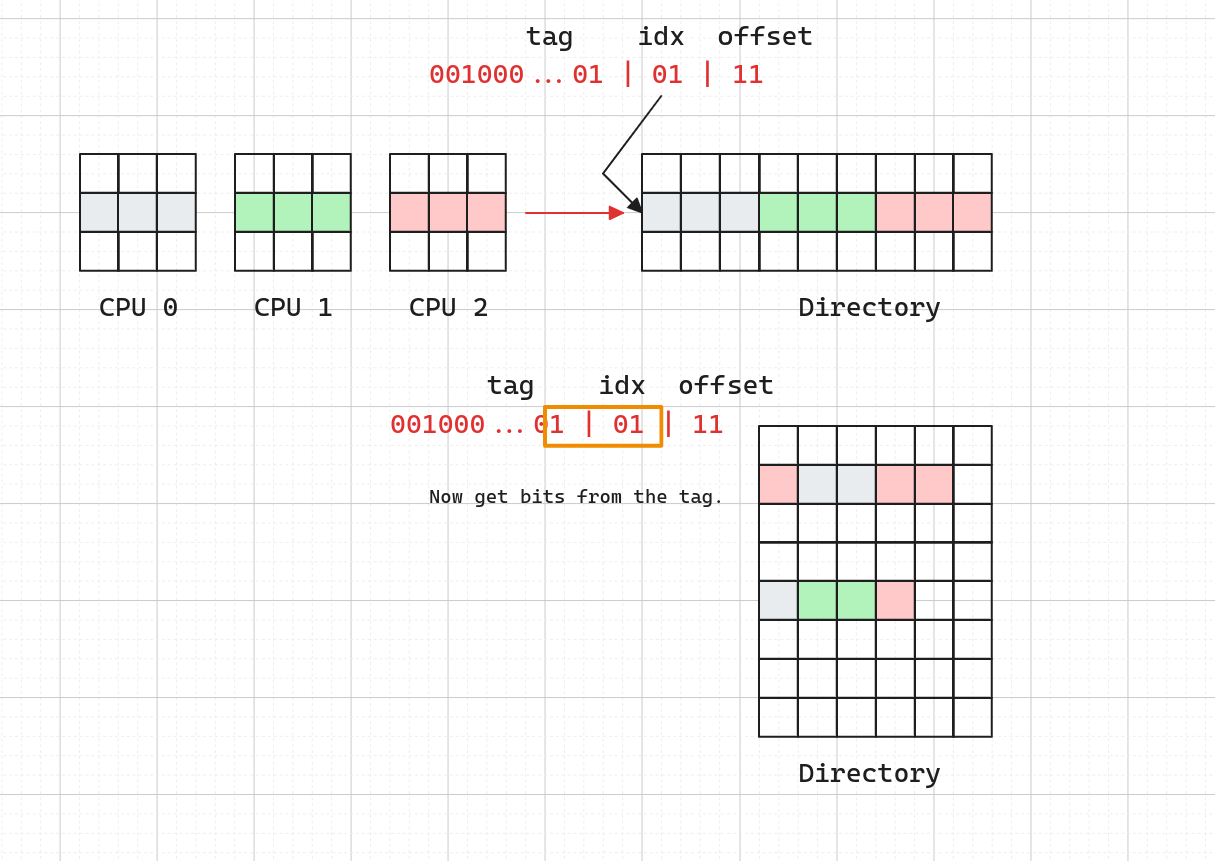
Current hardware use sparse directories. See the second illustration, so basically, we get some bits from tag bit while indexing the directory. In this way, we can build directories in a narrower fashion.
Interconnects
Bus is a shared communication channel which connects multiple components while interconnects are point-to-point communication channels.
For scalable communication through bus modern processors implement two types of interconnects:
- Ring: Cores, memory, and other components connected through a ring with 2 different lines with different directions.
- Mesh: Introduced with Skylake server processors.
Now ask your neighbors.
Protocols
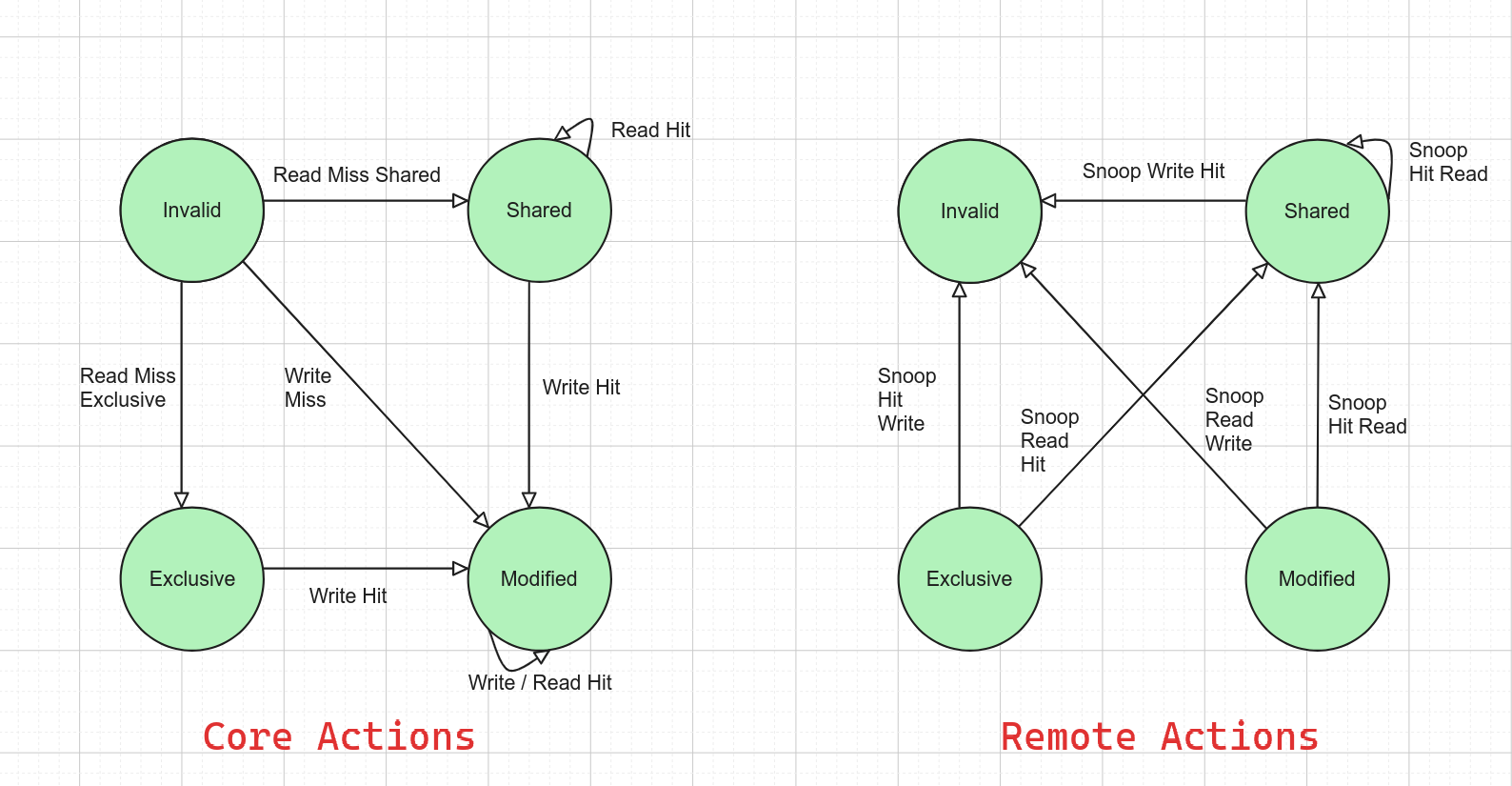
MESI Protocol
- Invalidate-based cache coherence protocol
- Also known as Illinois protocol
- MSI → MESI: we have
- Add an
Exclusivestate to reduce the traffic on the bus while accessing the cache line. We don’t need to broadcast others.
- Add an
States
- Modified: Write, that the cache has been updated.
- Exclusive: Read, but I’m the only owner.
- Shared: Read, but other caches also include this
- Invalid: -
However, scaling this communication through buses is not feasible. To overcome that there are point to point interconnects.
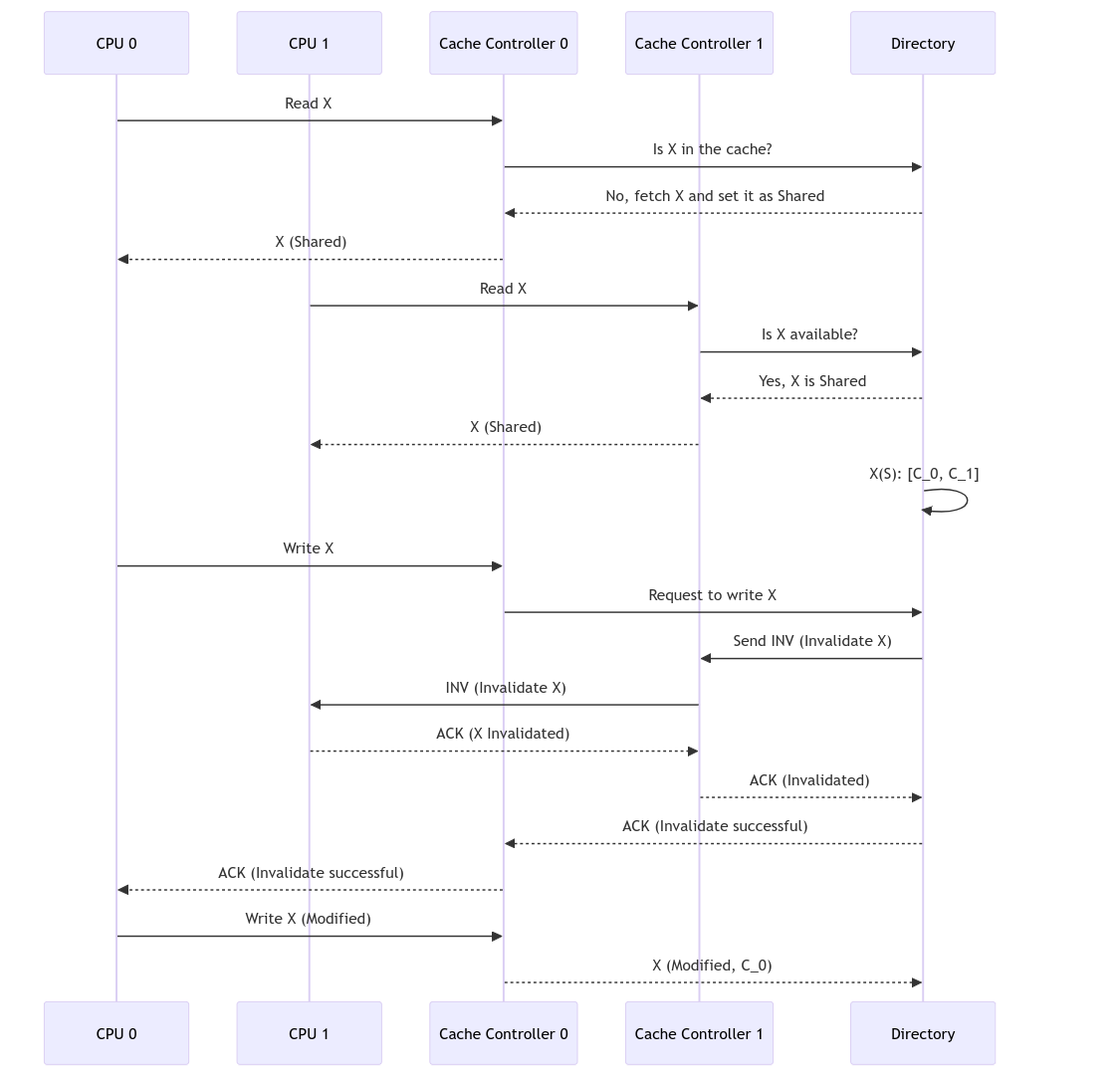
Example Assume MSI protocol. In here assume CPU 0 wants to read X. First cache controller checks if X is already in the cache or not. Then it asks for the directory. Directory sets X as Shared and gives to CPU 0.
Also CPU 1 gets the X. Now directory sees X(S): [C_0, C_1] Now CPU 0 wants to write X. To write it down first it needs to invalidate the state in CPU 1 Send INV message to CPU 1 When CPU 1 is invalidated its state sends back an ACK message. Then when the directory receives this message it sends back ACK to CPU 0, and then CPU 0 updates its state to Modified.
Current Architectures
TODO https://www.intel.com/content/www/us/en/developer/articles/technical/xeon-processor-scalable-family-technical-overview.html
CXL
TODO
References
- EPFL 307 Slides
- EPFL CS471 Slides
- https://en.wikipedia.org/wiki/Cache_coherency_protocols_(examples)
- Snoopy based coherence: https://www.cs.cmu.edu/afs/cs/academic/class/15418-s21/www/lectures/11_cachecoherence1.pdf
- Directory-based coherence: https://www.cs.cmu.edu/afs/cs/academic/class/15418-s19/www/lectures/13_directory.pdf
- MESI: https://www.youtube.com/watch?v=AAplcLi-2_Q
- The sequence diagram is generated by an LLM.
 This was the end of the blog post. You can reach me via email umusasadik at gmail com
This was the end of the blog post. You can reach me via email umusasadik at gmail com