Compilers
2020-07-23 |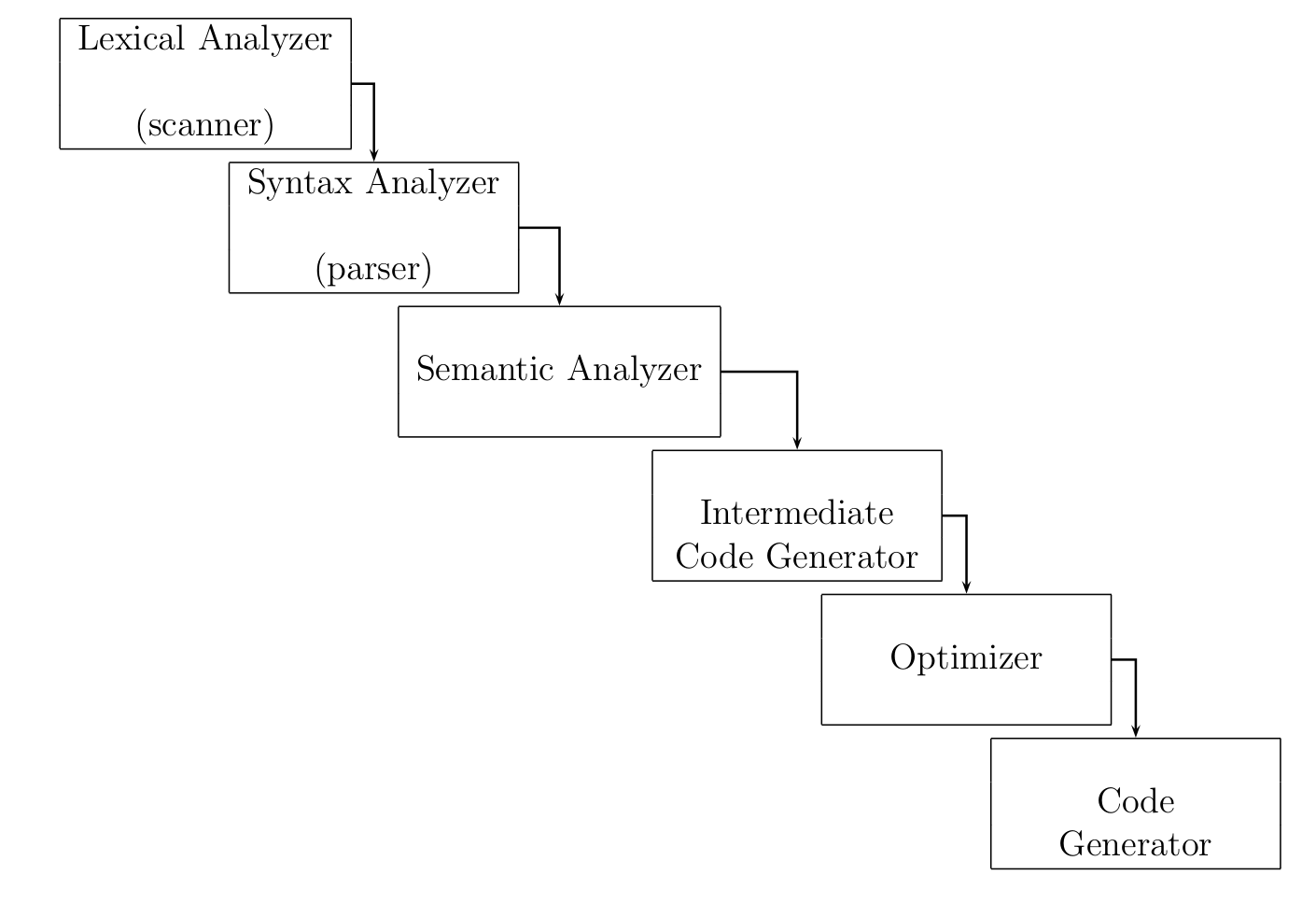
Front-end Compiling
The phase between lexical analyzer and semantic analyzer.
- Lexical analyzer: [Scanner] Divide into chunks, keywords
- Syntax analyzer: [Parser] Are sequence of chunks valid?
Backend Compiling
Also called as synthesizing. Get rid of from punctitions or other things.
Syntax And Semantics
- Syntax: How we write a sentence
- Semantics: What is the meaning of this sentence
We need a tool to express syntax which we called as Context Free Grammer.
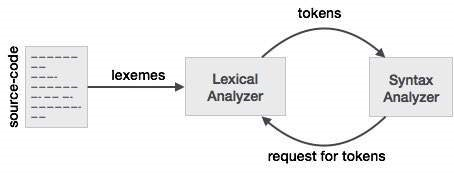
Syntax Basics
:::warning
* Token: functionality of the lexeme = tADD, tMULT ...
* Lexeme: + is a lexeme for tADD
:::
- Let's take an example about simple program
if (k) {
i ++;
}
If we write a lexical analyzer our program will generate these tokens:
tIF
tLBR
tIDENT
tRBR
tLCR
tIDENT
tPLUS
tPLUS
tRCR
| Token | Lexeme |
|---|---|
| tIF | if |
| tLBR | ( |
| tIDENT | variable... |
There some important facts about lexemes and tokens which are:
- A single token can be represented by multiple lexemes
- A lexeme can only represent a token.
Regex
Regex is a sequence of characters that specifies a search pattern [wiki].
Examples:
amathcesa[123]mathces1 or 2 or 3[1-8]mathces1 or 2 ....[a-z]matchesa,b ..[a-zA-Z]matches any letter[^a-zA-Z]matches any non-letterA+matchesA,AA ...A*matches,A,AA ...[a-zA-Z]*any string[0-9]+any number[a-zA-Z]{9}matches any 9 character string[a-zA-Z]{2,}matches any string len(str) > 2-?zero or one repeated
Flex
Flex stands for fast lexical analyzer.

%%
[a-z]* return tLSTR;
[A-Z]* return tBSTR;
[0-9]* return tNUM;
<<EOF>> return 0;
.
%%
main() {
yylex();
}
:::border
flex scanner.flx
gcc lex.yy.c -lfl
:::
Important Notations
yytext: String that matches with regular expressionyyleng: Length of string that matchesREJECT: Reject match go down
Conditions
- Pre-defined condition is
INITIAL.
%x comment
%%
"/*" BEGIN(comment);
<comment>"*/" BEGIN(INITIAL);
%%
Example Program - Not Optimized
int noOfLines = 1;
int search_pos(char * str, char a){
int k;
for (k = 0; k < strlen(str); k++) {
if(str[k] == a){
return k;
}
}
}
%x skipstr
DIGIT [0-9]
NONZERODIGIT [1-9]
CAPLETTER [A-Z]
LOWLETTER [a-z]
LETTER [{CAPLETTER} {LOWLETTER}]
STRING [{DIGIT}{LETTER}]
%%
\n noOfLines++;
\"([^\"]?)*\"
{
int k;
yytext++;
yytext[strlen(yytext)-1] = '\0';
printf("%d tSTRING (%s)\n",noOfLines,yytext);
for (k = 0; k < strlen(yytext); k++) {
if(yytext[k] == '\n'){
noOfLines ++;
}
}
}
Mail printf("%d tMAIL\n",noOfLines);
schedule printf("%d tSCHEDULE\n",noOfLines);
send printf("%d tSEND\n",noOfLines);
from printf("%d tFROM\n",noOfLines);
to printf("%d tTO\n",noOfLines);
set printf("%d tSET\n",noOfLines);
end\ Mail printf("%d tENDMAIL\n",noOfLines);
end\ schedule printf("%d tENDSCH\n",noOfLines);
[a-zA-Z0-9\.\-\_]+@([a-zA-Z0-9-]+\.){1,2}[a-zA-Z0-9]+
{
int atpos = search_pos(yytext,'@');
if(yytext[0] == '.' || yytext[atpos-1] == '.' || yytext[atpos+1] == '-'){
REJECT;
}
int k;
for(k = 0; k < atpos; k++ ){
if(yytext[k] == '.' && yytext[k+1] == '.'){
REJECT;
}
}
int l;
for(l = atpos; l < strlen(yytext); l++ ){
if(yytext[l] == '.'){
if(yytext[l-1] == '-' || yytext[l+1] == '-'){
REJECT;
}
}
}
printf("%d tADDRESS (%s)\n",noOfLines, yytext);
}
[0-9]{2}\/[0-9]{2}\/[0-9]{4} printf("%d tDATE (%s)\n",noOfLines,yytext);
[0-9]{2}:[0-9]{2} printf("%d tTIME (%s)\n",noOfLines,yytext);
[a-zA-Z_][a-zA-Z0-9_]* printf("%d tIDENT (%s)\n",noOfLines,yytext);
, printf("%d tCOMMA\n",noOfLines);
\: printf("%d tCOLON\n",noOfLines);
\( printf("%d tLPR\n",noOfLines);
\) printf("%d tRPR\n",noOfLines);
\[ printf("%d tLBR\n",noOfLines);
\] printf("%d tRBR\n",noOfLines);
\@ printf("%d tAT\n",noOfLines);
<<EOF>> return 0;
[^ ] printf("%d ILLEGAL CHARACTER (%s)\n",noOfLines,yytext);
.
%%
main() {
yylex();
}
Optimized
%{
#include "hw2.tab.h"
%}
tLOCALPART [A-Za-z0-9\-_]+(([A-Za-z0-9\-_]*|\.?)[A-Za-z0-9\-_])*
tDOMAIN [A-Za-z0-9]+[A-Za-z0-9\-]*[A-Za-z0-9]+|[A-Za-z0-9]{1}
%%
"Mail" return tMAIL;
"end Mail" return tENDMAIL;
"schedule" return tSCHEDULE;
"end schedule" return tENDSCH;
"send" return tSEND;
"set" return tSET;
"to" return tTO;
"from" return tFROM;
@ return tAT;
, return tCOMMA;
: return tCOLON;
\( return tLPR;
\) return tRPR;
\[ return tLBR;
\] return tRBR;
[a-zA-Z\_]+[a-zA-Z0-9\_]* return tIDENT;
["][^\"]*["] return tSTRING;
[0-9]{2}"/"[0-9]{2}"/"[0-9]{4} return tDATE;
[0-9]{2}:[0-9]{2} return tTIME;
{tLOCALPART}"@"({tDOMAIN}"."{tDOMAIN}"."{tDOMAIN}|{tDOMAIN}"."{tDOMAIN}) return tADDRESS;
[ \t\n]+
. return yytext[0];
%%
 This was the end of the blog post. You can reach me via email umusasadik at gmail com
This was the end of the blog post. You can reach me via email umusasadik at gmail com